The algorithm decribed here is a simplification of the one used in my thesis (1). So, for more information, see the thesis
.![]()
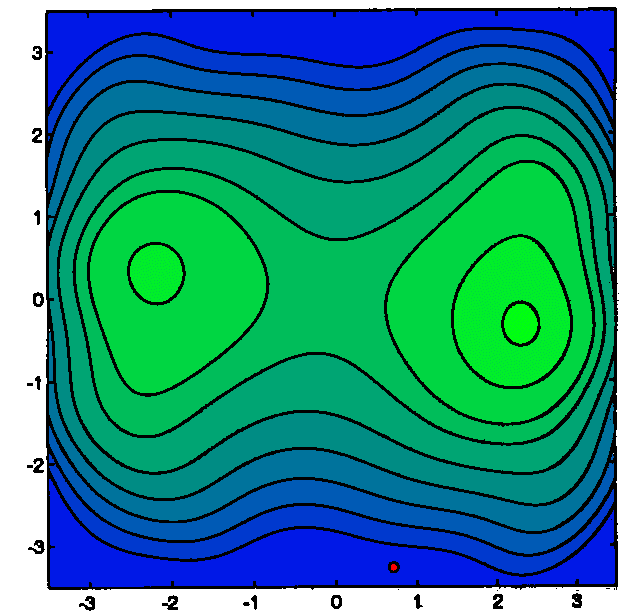
We will construct a local approximation Q(x) of f(x) around ![]() .
Q(x) is a polynomial of degree 2. Q(x) is represented in the figure below with
bold lines. We will define a Trust Region around the current point
.
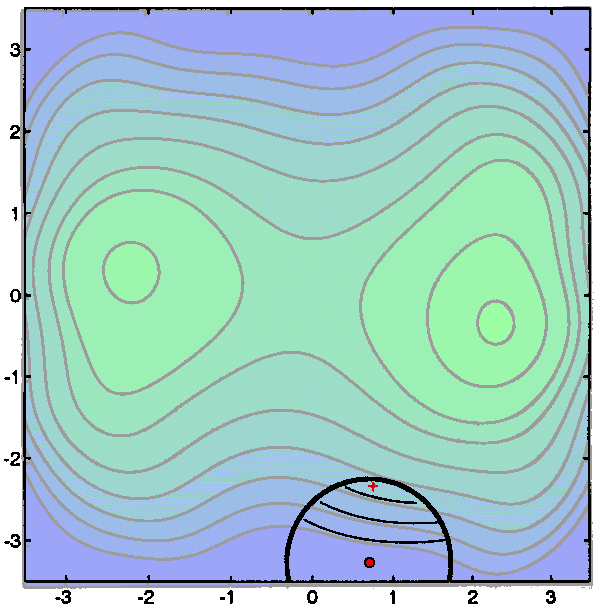
Q(x) is a polynomial of degree 2. Q(x) is represented in the figure below with
bold lines. We will define a Trust Region around the current point
![]() . The trust region
is a disc of radius
. The trust region
is a disc of radius ![]() centered at
centered at ![]() .We will
search for the minimum of Q(x) inside the Trust Region. This minimum
.We will
search for the minimum of Q(x) inside the Trust Region. This minimum ![]() is the red cross in the figures below.
is the red cross in the figures below.
We obtain  <
<
![]() : this is a success:
Q(x) is a good local approximator of f(x) and has given us a good advice. We
will move the current position to
: this is a success:
Q(x) is a good local approximator of f(x) and has given us a good advice. We
will move the current position to ![]() and
iterate (k:=k+1). Since Q(x) is so good we will also
increase the trust region radius
and
iterate (k:=k+1). Since Q(x) is so good we will also
increase the trust region radius ![]() .
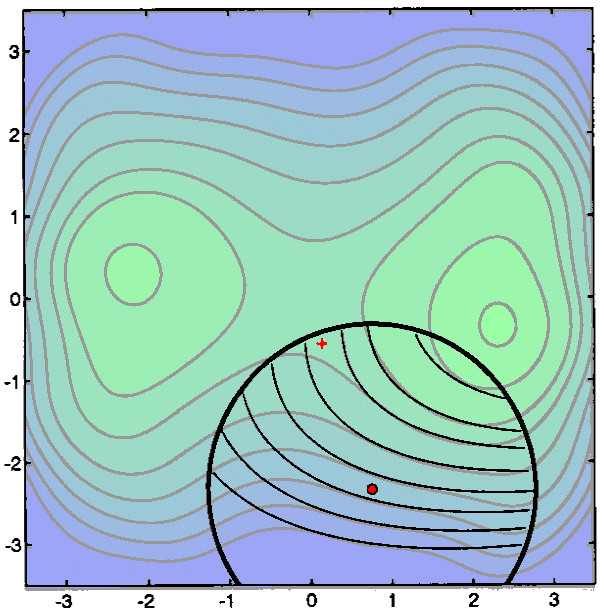
We will re-contruct a new quadratic interpolation Q(x) around the new
.
We will re-contruct a new quadratic interpolation Q(x) around the new ![]() .
This re-construction can induce many evaluation of the objective function. In
fact, in most optimization algorithms, this is where the greatest number of
function evaluations are spend. In the algorithm developped, I use a special
heuristic due to powel(2) to reduce the re-construction cost. This heuristic
is based on Multivariate Lagrange Interpolation Polynomials. There are also
other possibilities to construct Q(x) like the BFGS method. See the figure below
for a graphical explanation of the second step of the algorithm.
.
This re-construction can induce many evaluation of the objective function. In
fact, in most optimization algorithms, this is where the greatest number of
function evaluations are spend. In the algorithm developped, I use a special
heuristic due to powel(2) to reduce the re-construction cost. This heuristic
is based on Multivariate Lagrange Interpolation Polynomials. There are also
other possibilities to construct Q(x) like the BFGS method. See the figure below
for a graphical explanation of the second step of the algorithm. ![]() (the red cross) is once again the minimum of Q inside the Trust Region.
(the red cross) is once again the minimum of Q inside the Trust Region.
We obtain, once again, a success: <
![]() . We move to the
new position.We Reconstruct Q(x).
. We move to the
new position.We Reconstruct Q(x).
We Increase ![]() .
.
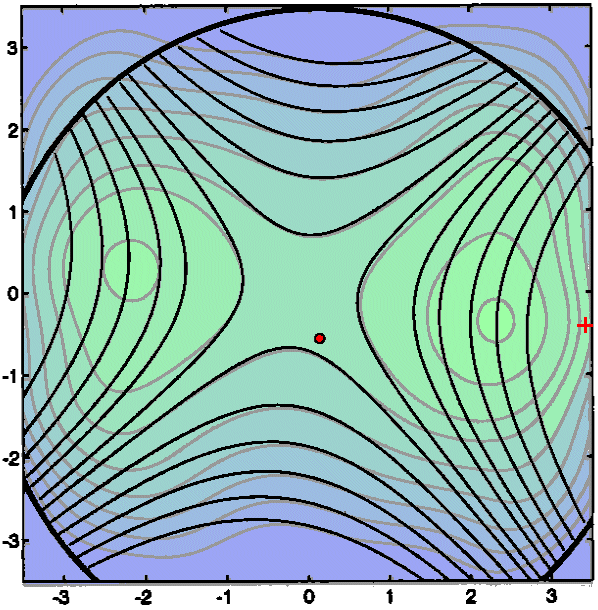
This will be a failure: >
![]() . Q(x) is not anymore
a correct approximation of f(x). We thus reduce
. Q(x) is not anymore
a correct approximation of f(x). We thus reduce ![]() . The current position
. The current position ![]() is not changed.
is not changed.
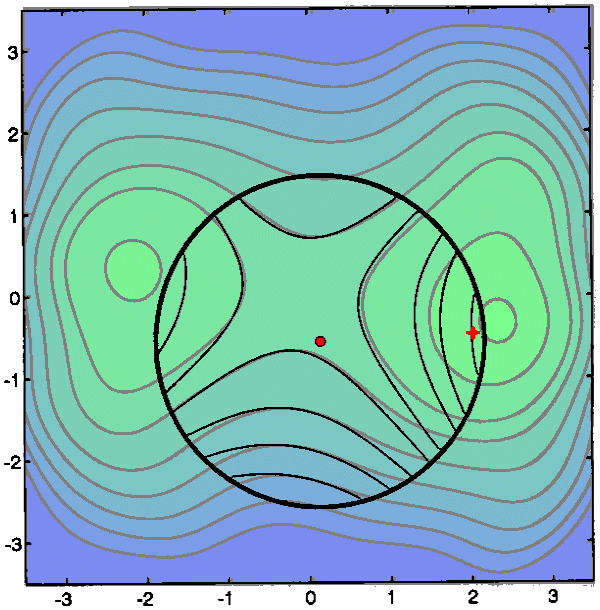
This is a partial success: <
![]() but the reduction
is not as big as predicted by Q(x), so we do not change
but the reduction
is not as big as predicted by Q(x), so we do not change ![]() . The current position
. The current position ![]() is moved.
is moved.
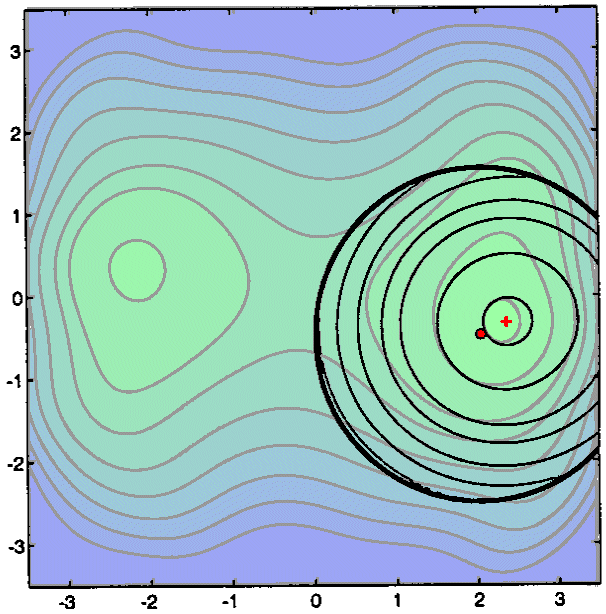
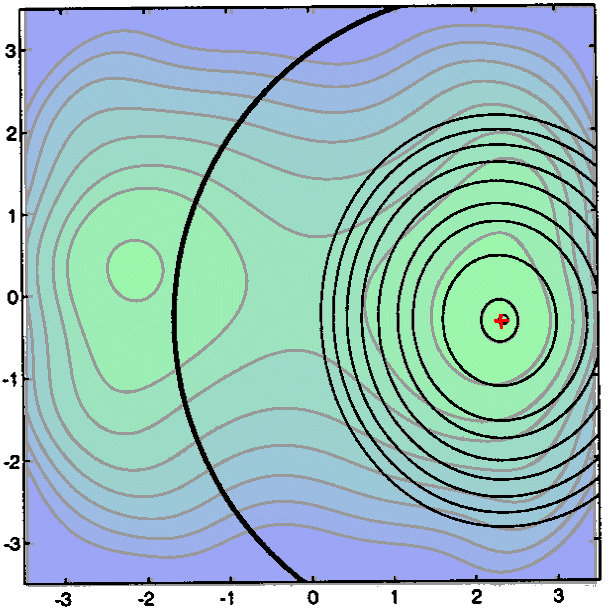
The next iterations do not exhibit anything new. Note that the trust region
radius ![]() is becoming
very huge at the end of the search. We stop when the step size (=||
is becoming
very huge at the end of the search. We stop when the step size (=|| ![]() -
- ![]() ||)
is becoming too small
||)
is becoming too small